Student Projects
VE/VM450
Learning To Dispatch And Reposition On A Mobility-on-demand Platform
Sponsor: Dr. Guobin Wu, DiDi
Team Members: Lingyun Guo, Jiachen Liu, Yifei Zhang, Siyi Zheng, Yuankun Zhu
Instructor: Prof. Mian Li
Project Video
Team Members

Team Members:
Lingyun Guo
Jiachen Liu
Yifei Zhang
Siyi Zheng
Yuankun Zhu
Instructor:
Prof. Mian Li
Project Description
Problem Statement
Ride-hailing service is changing the way of modern travelling. DiDi Chuxing application provides a convenient ride-hailing service for people to place an order nearly everywhere they wish and wait for drivers to pick them up at the location they specified. This Mobility-on-Demand (MoD) platform suits the convenience of both passengers and drivers. However, passengers still want to minimize the pick-up distance and order response time, whereas drivers want to maximize their income. Supported by our sponsor, our project objective is to propose an algorithm to achieve optimal benefits for both parties.
![Fig. 1 Problem division [1]](https://www.ji.sjtu.edu.cn/wp-content/uploads/2020/07/450-4-pic01.jpg)
Fig. 1 Problem division [1]
Concept Generation
Our problem can be viewed as a live interaction system between idle drivers from the platform and orders generated from the environment. We model the environment with a simulator and use the reinforcement learning algorithm to learn the platform’s dispatching and repositioning policy for drivers.
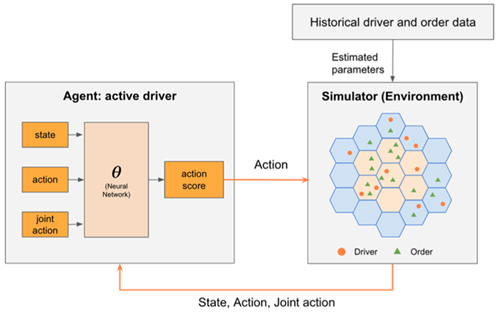
Fig. 2 Concept Diagram
Simulator Construction
We construct the simulator from real-world statistics. The raw data consists of hexagon grid, order request, driver trajectory, and order cancellation probability for November 2016. Grids are selected from the central region of the city, covering 98.8% of the orders in total. Duration and reward of orders are treated as normal distribution and parameters are inferred with statistical analysis. Driver’s online duration are estimated by the difference between the departure time of the first order and the completion time of the last order of a day.
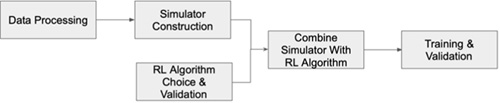
Fig. 3 Flow Chart of Algorithm Construction
RL Algorithm
We adopt Mean Field Deep Q Learning [2] as main algorithm. It is based on mean field approximations, which helps us consider other agents’ actions with variable population sizes.
We approximate each state-action-joint action pair by neural network.
Actions are chosen by the Boltzmann Softmax selector:
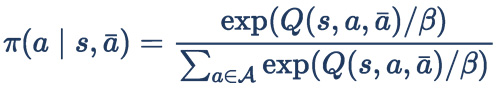
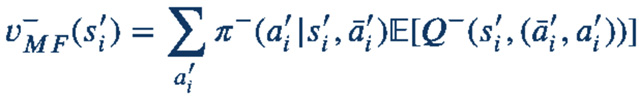
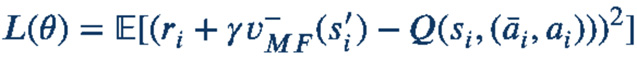
Validation
Validation Process:
We train the model for several episodes and observe the obtained reward. Our implementation could handle the computation for the entire city efficiently within 2 seconds each step and is robust to different inputs. The training results prove that out algorithm is effective.
Validation Results:
As specified in the validation process, our implementation could meet all the specifications:
√ Computational time <= 2s
√ Scale covers entire city
√ Average cumulative reward >= 5%
√ Performance stable under noise
√ Exception rate -> 0
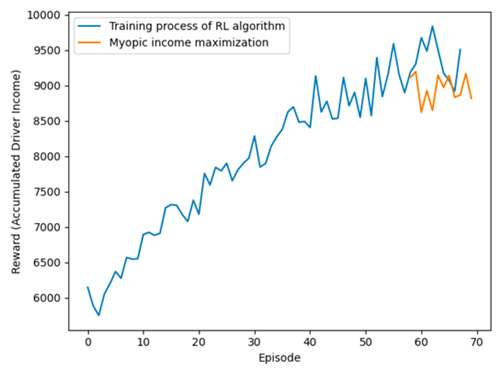
Fig. 4 Algorithm Performance
Conclusion
We apply Mean Field Deep Q learning to address order dispatching and driver repositioning. We construct a simulator with real-world data for the training process and design several animation schemes to interpret our method. Experimental results show that our approach is valid.
Acknowledgement
Sponsor: Dr. Guobin Wu, DiDi
Instructor: Prof. Mian Li
Reference
[1] Overview of Didi KDD Cup 2020. May 16, 2020. url: https : / / www . bilibili . com / video / BV17i4y147K1?from=search&seid=1345137660262068789 (visited on 06/11/2020).
[2] M Li, Z. Qin, and Y. Jiao. “Efficient Ridesharing Order Dispatching with Mean Field Multi-Agent Reinforcement Learning”. In:The World Wide Web Conference on – WWW 19(2019).